CoinAPI Data Pull
Create the table
So, how do we aquire data for the top ten crypto coins?
To start I created an account with CoinAPI to get a secret key to access their API.
Once I had this API key, I had to get the data from the API and into a database for storage. So, first I created a PostgreSQL database on Render.com. Being that
this was going to be a simple table that would only hold the values from the CoinAPI, I didn't need to go crazy in creating anythin beyond a First Normal Form.
My table in this case looks like this:
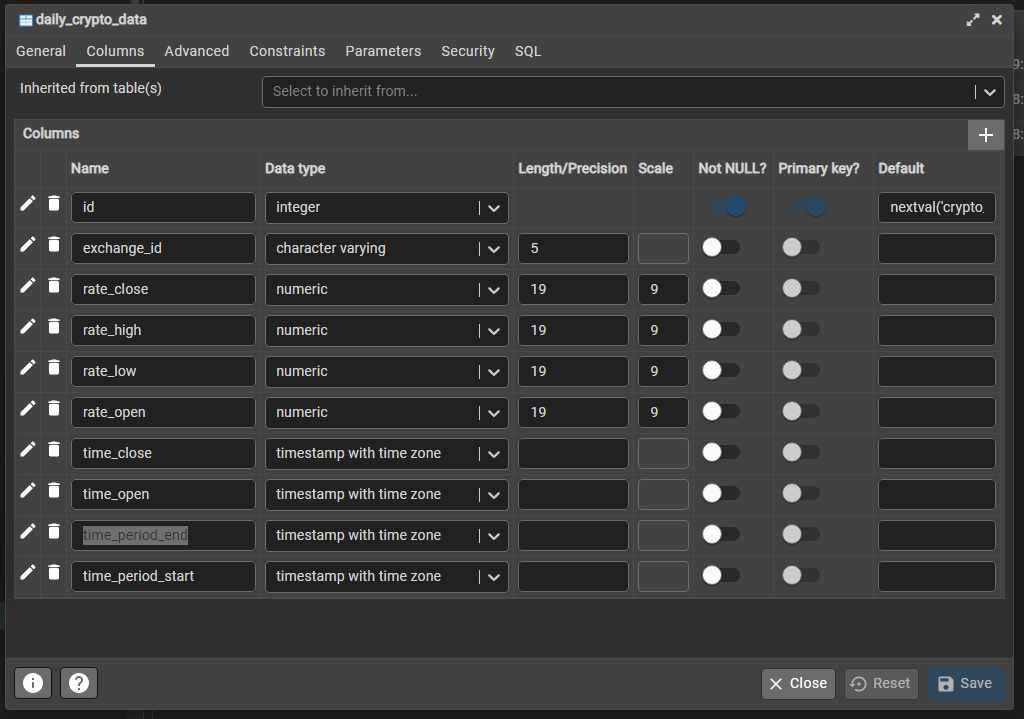
- id: Primary Key of the table, useful for indexing and building SQLAlchemy models in Flask
- exchange_id: VARCHAR column to hold the shortened version of each coin name
- rate_close: Numeric column to hold the closing dollar value for that time period
- rate_high: Numeric column to hold the high dollar value for that time period
- rate_low: Numeric column to hold the low dollar value for that time period
- rate_open: Numeric column to hold the opening dollar value for that time period
- time_close: Datetime in UTC for the closing time of each time period
- time_open: Datetime in UTC for the opening time of each time period
- time_period_end: Datetime in UTC for the time period end of each time period
- time_period_start: Datetime in UTC for the time period start of each time period
Load the libraries and the secrets
Ok, the table's created! Now, we need to populate it.
Our custom script needs to accomplish four things:
- Connect to the API
- Translate the return object into JSON
- Load the JSON into a Pandas DataFrame
- Load that DataFrame into the DB table
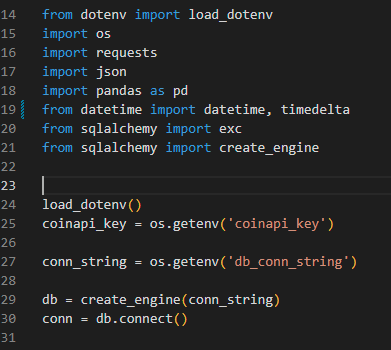
Ok, we've loaded the usual suspects into the script. Using a .env file, we'll store the really important secret sauce:
- CoinAPI Secret key
- Database access info (address, username, and password)
Now we can use SQLAlchemy to create the connection engine (create_engine) and the connection we need to write the data to the DB.
Create some variables

In order to call to the API and get back the proper response we are expecting, we need to pass some information to the API:
- Today's date in this format: YYYY-MM-DDT00:00:00 ex: 2022-12-12T00:00:00
- Yesterdays date in this format: YYYY-MM-DDT00:00:00 ex: 2022-12-11T00:00:00
- An empty DataFrame to add values to
- i. Because i is important. It can count.
The next step would be to convert today's and yesterday's date into the correct format to include T00:00:00 time so the API call would only get data from yesterday. I used f-strings and .strftime() to accomplish this. It looks like this:
- yesterday = f"{yesterday_date.strftime('%Y-%m-%d')}T00:00:00"
- today = f"{datetime.now().strftime('%Y-%m-%d')}T00:00:00"
Ok, we now have datetimes for yesterday and today, an empty DataFrame, and a counter variable. Time go get calling!
Call the API
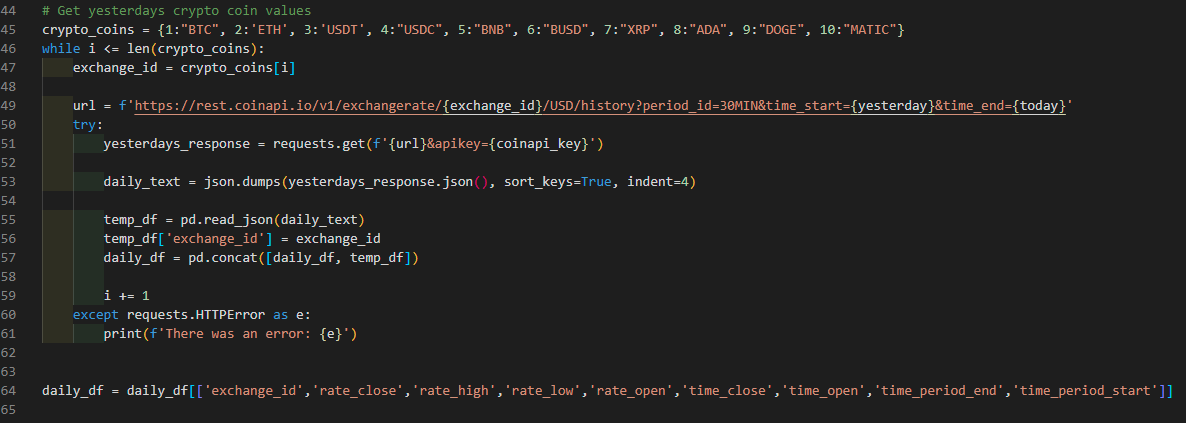
One of the variables that gets passed to the API call is the specific cryto coin symbol. But, for me to pull multiple coins I would have to change the symbol each time.
So, to fix this I created a dictionary of number and symbol pairs. This will be useful when we loop over the API call.
How are we going to be able to run this command multiple time, you might ask? Well, it's time to run a while loop.
If we look at the while loop of line 46, we see that it essentially says, while i is less than the biggest number in the dictionary repeat everything that follows.
Now that we're in the loop, we set the variable (exchange_id) equal to the value that is paired to the key value. IE if i is equal to 1, the value will be BTC.
All right, we now have our exchange_id, today, and yesterday. With these variables we use a f-string variable to create the url we're going to call when we run the request.
The next part we come to is a try. What does try do? Just that. Try doing this bunch of code until an error occurs.
In this case, I want the code to execute a function called request.get() to send the request and API key to the API and get an response back.
One curious thing about this url we're using to make the request is this part "period_id=30MIN", this allows me to specify that the data should be based on 30 minute intervals.
Next, we need to translate this response to a JSON object. This is needed to easily translate into a DataFrame.
We also need to add the exchange_id to each line that goes into the DataFrame. That empty DataFrame we created? Now it's time to add this data into that empty DataFrame using the pd.concat() function.
Sweet! We have our data for the previous 24 hours in 30 minute increments saved in a Pandas DataFrame... now what..?
Before we can load it to the table, we need to make some changes to the DataFrame to make it easier to load to the DB.
This is accomplished by using some trickery in Pandas to rearrange the columns to match the layout of the table itself by running line 64.
At this point, we're specifying what columns are going into the DataFrame and what order they are in.
If we need to run any additional cleaning or transformation of the data, this would be where it's done. But, thankfully our data is relatively simple so no additional cleaning or prep is needed.
Upload the data to the DB table
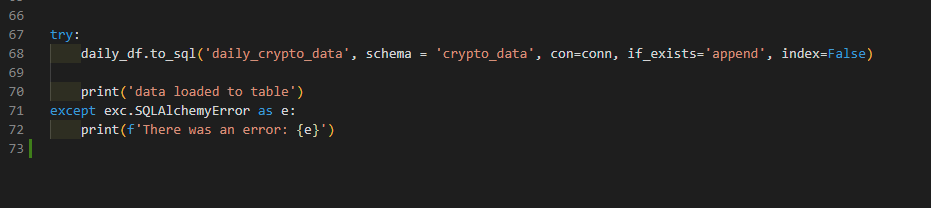
The final task we have before us after we have downloaded and cleaned our data, is to load it into the database table we build specifically for this.
Thankfully, we are going to use the builtin function that Pandas brings to the party: to_sql(). With just a few options to specify which table the data is going to, the schema the table is in, how we're connecting to the
database, how to react if the table already exists, and finally whether to include the DataFrame index or not.
Normally, when you write data to a table, you would have to close out the statement by running a commit of some kind, in this case, SQLAlchemy does this for us.
Automate the boring stuff
So, we have a script that can connect to an API, pull data, clean the data, and then load it into a DB table. Awesome! But wait, I don't want to run this everyday manually! Thankfully, automation is available. There are many tools we can use to automate this action AWS, Azure, Google Cloud, and a host of other services offer tools to run code in an automated fashion. I chose to accomplish this by using Render to connect to my GitHub, build a pipeline, and use Cron to schedule the job to run automatically at midnight UTC time. Thus, I no longer have to worry about running this script everyday to update my data that I'm pumping into a dashboard located here.
If you want a copy of the code I used to build this ETL script you can find it at my CoinAPI Call repo.